

measurement, discrimination, and large technology companies
measurement, discrimination, and large technology companies
how some technology companies are turning to inference, perception, and collection of demographic data to measure discrimination on their services

say you’re a large technology company. your company is involved in connecting people in some way. maybe you sit in the middle and connect people who are looking for a new job and people who are offering jobs. or maybe you sit in the middle between someone who is offering a short-term rental and someone who is looking for a four night stay in The Dalles in Oregon.
if you’re a product manager at one of these companies, you might have some sense that a couple things could be true:
your core products might not be experienced equitably by people of differing races, ethnicities, or gender identities. for example, the service you offer connects
rentersandhosts, but certain renters disproportionately have their requests to book denied.your core products might not be operating in an equitable manner. for example, the service you offer ranks candidates based on
job typeandlocation, but certain candidates consistently appear more often after page five of the search results, and others disproportionately appear in the first few pages.
in fact, some civil rights groups might have come and told you this, based on a range of anecdotal experiences or even peer-reviewed academic research. and your boss and your boss’s boss tells you that you need to figure it out. so where do you start?
depending on how plugged in you have been to the “how do large technology companies measure and remediate discrimination in their products and services” space, you may or may not have recognized these examples as not so hypothetical. there’s a lot going on, so, pretty fair if you aren’t. anyway, these examples are very real! Airbnb, LinkedIn, and Meta are three large technology companies that have all tried to figure this out in some way. the “this” is:
figuring out ways to measure discrimination on their services and in their products when basic demographic data about users may or may not be available;
taking some sort of corrective action, either in changing how the product operates at a policy or design level, implementing some sort of algorithmic system to counteract discrimination, or both.
these companies have taken slightly different approaches, for what are probably reasonable reasons. but two is a coincidence and three is a trend, as they say. why does that trend matter?
first, these aren’t just “large technology companies.”1 these are all companies that in some meaningful sense engage in commerce in traditionally covered civil rights areas. LinkedIn wants to help you get a job or help you hire someone. Airbnb wants to help you find a place to stay or to rent your room or home. Meta wants you to spend all of your advertising budget for basically any employment, housing, or credit opportunity so you can reach a bunch of theoretically interested consumers. putting aside whether or not each of these companies actually is covered by the relevant civil rights laws,2 it’s had to dispute that these companies clearly engage in business in a way that is relevant to civil rights.
second, it matters how these companies approach the problem. for whatever reason, these companies might not want to directly collect demographic data.3 as a result, they might turn to other methods like inference or perception. there are a lot of tricky aspects to this process when it comes to categories such as race and gender. as professor wendy roth notes, there are:
multiple dimensions of the concept of race, including racial identity, self-classification, observed race, reflected race, phenotype, and racial ancestry. With the word ‘race' used as a proxy for each of these dimensions, much of our scholarship and public discourse is actually comparing across several distinct, albeit correlated, variables. Yet which dimension of race is used can significantly influence findings of racial inequality.
in other words, the race someone self-identifies as might be different than the race an individual identifies with on a government form, which might be different than the race others believe them to be.4 each of these companies has pretty in-depth technical papers that describe the methods used to measure and remediate discrimination. you can find Airbnb’s here, LinkedIn’s here, and Meta’s here and here.
this post is the first in a series on measurement of discrimination.
Part One will focus on the problems some large technology companies have confronted, the approaches to measurement they’ve taken to assess discrimination on their services, and how that measurement has informed the policy or product response.
Part Two will focus on some of the laws and policies governing collection of demographic data in traditional civil rights areas. Why is collection prohibited in some instances? What is the regulatory history?
Part Three will focus on inference methods and the tooling that companies turn to when they cannot collect demographic data directly from users, whatever reason that might be.
Part Four will try and connect these threads. From first principles, how do we want large technology companies to measure discrimination on their services? If there is an expectation that companies perform disaggregated
evaluations of their models and products, what is the optimal way to do so, given certain constraints? Should this be a regulatory requirement or stay voluntary? If it should be a legal requirement, what law and policy changes might be necessary?
Airbnb’s Project Lighthouse
in repsonse to #AirbnbWhileBlack, the company formed a “permanent anti-discrimination product team.” one focus of that team was project lighthouse, which sought to “measure the rate at which guests from different perceived racial groups in the US successfully book an Airbnb listing,” which they term the “Booking Success Rate.” the goal of the project is to “to create better tools and policies to combat bias and discrimination on our platform,” rather than to address some algorithmic system. in other words, to goal is to use the data obtained from measurement to influence policy and product design.
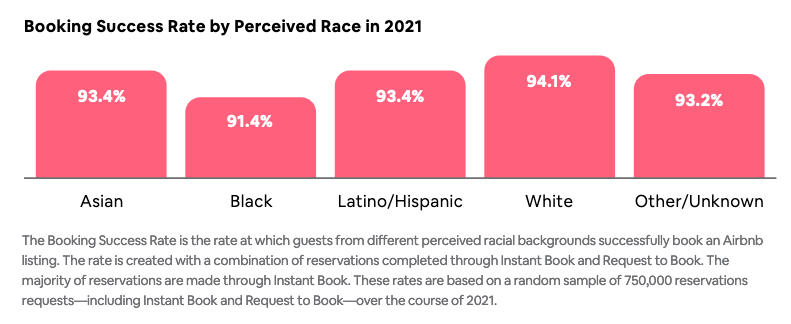
you might have caught a key word: “perceived race” — not how someone might identify themselves. which makes some sense: if your theory is that hosts may be taking disparate actions based on how they perceive potential guests as a result seeing a potential guests’ picture or reading their first name, measuring how individuals might perceive someone makes some conceptual sense.
here’s the approach Airbnb crafted to measure perception:
Airbnb contracts with a Research Partner, who has to meet a bunch of criteria;
Airbnb provides that Research Partner pairs of first names and photos of Airbnb hosts or guests. the Research Partner receives something that might look like this:

the Research Partner assigns a perceived race to each pair of first names and photos (notably this is all the human perception of race and the partner is prohibited from using algorithms for computer perception of race).

why perception and not inference? after all there are racial inference methods, such as BISG or BIFSG. here’s what Airbnb has to say:
This project measures discrimination that’s based on perception. People often base their perception of someone’s race on their name and what they look like. So, to get these perceptions, we’ll share Airbnb profile photos and the first names associated with them with an independent partner that’s not part of Airbnb.
Airbnb has suggested that this research taught them that Instant Book — which don’t require a host to review prior to approval — is “one of the most effective tools to increase the Booking Success Rate across perceived racial groups.”5
LinkedIn’s Representative Results
As reported in the MIT Technology Review in 2021:
Years ago, LinkedIn discovered that the recommendation algorithms it uses to match job candidates with opportunities were producing biased results …. The system wound up referring more men than women for open roles simply because men are often more aggressive at seeking out new opportunities.
so what’s going on here? imagine you’re a recruiter using LinkedIn Recruiter to search for a Software Engineer in Seattle, WA. to serve you relevant results, LinkedIn first builds a list of “qualified applicants” based on your criteria (here, your two relevant criteria Software Engineer and Seattle, WA). next, LinkedIn uses a range of criteria to rank that list of qualified applicants. LinkedIn says some of these criteria include things “such as the similarity of their work experience/skills with the search criteria, job posting location, and the likelihood of a response from an interested candidate.”
this process of building a qualified pool and then ranking resulted in biased results for a few reasons, according to LinkedIn’s former VP for Product Management:
we found for example, that men tend to be a little bit more verbose, they tend to be a little bit more willing to identify skills that they have maybe at a slightly lower level than women who have those same skills who would be a little less willing to identify those skills as something that they want to be viewed as having. so you end up with profile disparity, that might mean there’s slightly less data available for women.
other signals included “how often have you responded to messages, how aggressive are you when applying for jobs, how many keywords did you put on your profile whether or not they were fully justified by your experience.”
in an attempt to correct for the gender skew in Recruiter, LinkedIn developed a re-ranking system:
the operating definition of “equal” or “fair” here is towards achieving ranked results that are representative (in terms of the attribute of interest, and in the scope of this work, inferred gender) of the qualified population. We define qualified population to be the set of candidates (LinkedIn members) that match the criteria set forth in the recruiter’s query (e.g., if the query is “Skill:Java,” then the qualified population is the set of members that are familiar with computer programming using the Java programming language).
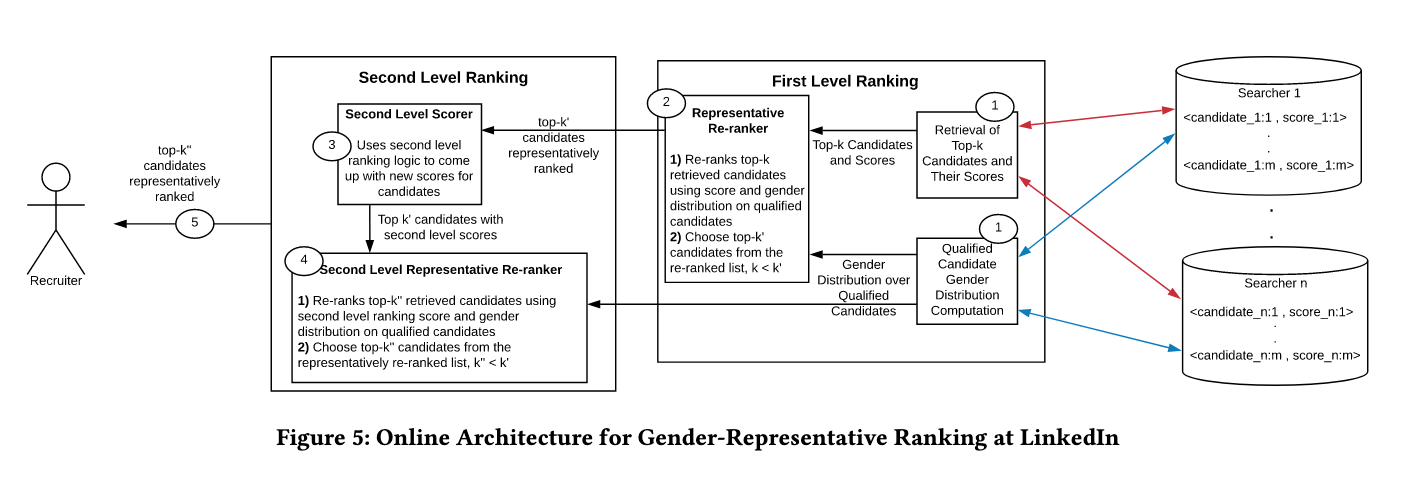
so first LinkedIn has to measure gender. given that measurement, it can then calculate the gender ratio of a given “qualified applicants” pool retrieved by LinkedIn in the first instance. then, a re-ranking process ensures that each page of candidates presented to a recruiter maintains a gender ratio that is similar to the ratio from the overall set of qualified applicants.
you might very reasonably be asking “how does LinkedIn measure gender”?

notably, LinkedIn users can also enter their demographic information to self-identify.
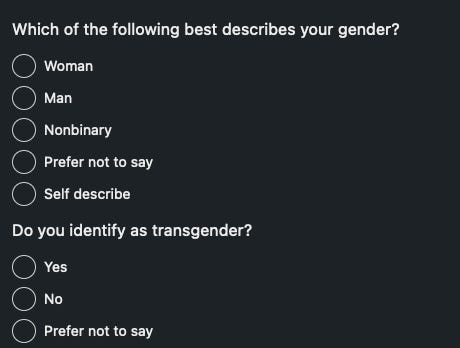
so LinkedIn may infer your gender based on information in your profile, which from what I can gather can happen in a couple different ways:
LinkedIn might use the information when you self-describe how you identify.
this seems to literally not be what it means to “infer” something. so perhaps it’s better to say sometimes LinkedIn collects self-reported gender from its users.LinkedIn might infer gender from pronouns in a profile. those pronouns might come from a user placing them in their profile, or from a third-party offering a recommendation of that user and using certain pronouns in their recommendations.
LinkedIn might infer gender from a user’s first name.
based on how LinkedIn describes a separate service, called diversity nudges, it seems that the inference at play here assumes a gender binary, to the exclusion of transgender and non-binary people. Part Three of this series will try and think through what’s going on here.
Meta’s Variance Reduction System
this is a long story, so here is a tl;dr:
2016: ProPublica revealed that Facebook allowed its advertisers to exclude people from seeing housing ads based on their “ethnic affinity.
2016-2018: a bunch of lawsuits happen.
2019: Facebook settled those lawsuits. under the settlement Facebook:
created a new portal for housing, employment, and credit (“HEC”) ads;
removed gender, age, and affinity targeting options;
changed its “Lookalike Audience” tool and created the Special Ad Audiences tool that does not consider users’ age, gender, relationship status, religious views, school, political views, interests, or zip code when detecting common qualities;
required advertisers to self-certify they aren’t discriminating;
develop some automated systems to detect if an ad is a HEC ad to ensure it’s properly routed to the HEC portal.
2019: the United States Department of Housing and Urban Development charged the company for “encouraging, enabling, and causing” unlawful housing discrimination.
2019: a series of research papers demonstrate that discrimination persists in Facebook’s delivery of housing, employment, and credit ads and that the Special Ad Audiences tool still led to skewed outcomes. the research demonstrated significant bias in Facebook’s ad delivery decisions on the basis of gender, age, and other protected characteristics, even when an advertiser chooses to target their ad towards all gender and age groups.
2021: on the same day, the Department of Justice filed its complaint in federal district court (after Facebook elected to have the charge decided in federal district court) and the DOJ and Meta reached a settlement agreement (clearly, a lot of background work on the settlement had been happening). that settlement requires a number of things
2023: the DOJ and Meta reached agreement on the ad variance reduction system’s compliance targets, as required by the 2021 settlement agreement.
Meta releases a technical paper, explaining how it will implement its Ad Variance Reduction System (VRS).
okay. the upshot of the settlement is this VRS. how does it work?
the VRS is an “offline reinforcement learning framework with the explicit goal of minimizing an ad’s impression variance across the demographic subgroups.” specifically, the VRS will “rely on a controller that has the ability to change one of the values used to calculate an ad’s total value in our ad auction, which will have the effect of changing the likelihood that a given ad will win an auction and be shown to a user. The value that the controller will be able to adjust is called the pacing multiplier, which is adjusted through a boost multiplier.”
there are a few steps. first, the VRS starts up after an HEC ad wins an auction and is shown to Facebook users. once the ad has been shown to a sufficiently large number of Facebookers, VRS measures the aggregate age, gender, and estimated race/ethnicity distribution of the Facebookers that “saw” the ad. to perform this measurement, Meta relies on a version of BISG they developed, more on this in Part Four of the series). those measurements of Facbook users shown a HEC ad are then compared against the eligible ad audience selected by the advertiser. if there’s a difference between those two, the VRS is instructed to adjust pacing multipliers for an ad in order to reduce the variance.
notably, eligible ad audience selected by the advertiser is, you guessed it, a function of advertiser targeting criteria. and while Meta has removed a number of targeting features, it’s still possible that if an advertiser wanted to create a sufficiently exclusionary targeting criteria, they’d probably be able to and VRS doesn’t really have anything to say about that. Meta might say this kind of behavior violates their policies and they require advertisers to certify they aren’t going to do something that violates civil rights law. who knows.
Next time
one of these efforts (LinkedIn) is voluntary. one of these efforts (Airbnb) is semi-voluntary — semi-voluntary in the sense it came in response to external pressure from customers and civil rights groups, but voluntary because they could have of course done nothing. one of these efforts is the result of a legal process. next time, I’m going to try and excavate some of the history regarding the the laws and policies governing collection of demographic data in traditional civil rights areas.
it’s not even clear what the phrase ‘large technology company’ means these days. i guess that’s a similar descriptor to “big tech.” what is that though? putting aside the measurement of what’s “big” or “large,” is wal-mart a technology company? in some senses yes — it relies on a ton of technology to offer its core services. in some other sense, if you told your parents that you picked up some seltzer from wal-mart, the large technology company, they’d think something was wrong with you.
as an example, some might argue that LinkedIn is in fact covered by Title VII as an “employment agency,” while I’m sure LinkedIn’s lawyers would not agree.
they might want to avoid a headline that says “large technology company is collecting race data on their users.” even if that process was part of a clear civil rights monitorship or settlement and was explicitly only for anti-discrimination work, well i am explicitly not a pr or press person, but i can imagine them being worried how that would play out in public messaging.
notably, Airbnb also says that “[w]hile Instant Book is effective at reducing racial disparities in the Booking Success Rate, Project Lighthouse found a gap in the ability of guests from different perceived races to access Instant Book. For example, the analysis found that a large percentage of guests perceived to be Black or Latino/Hispanic are first-time users of the platform and often do not meet Host-selected criteria to use Instant Book because they do not yet have a history of reviews.” as a result of that observation, Airbnb updated “the ‘Host recommended’ eligibility criteria for Instant Book to a “good track record” requirement, to be more inclusive of people who have fewer stays and reviews.”